Nancy Drew Data Investigation #1: Lost in the Lexicons
“Wow, that book was great!” said Grace as she wrapped up another installment in the Nancy Drew Files series. “Nancy’s life is so exciting, but it seems like she’s always getting herself into trouble.” Grace didn’t remember there being this much mortal peril in the original Nancy Drew Mystery Stories!
If you can’t already tell, this post – and more to come – is about Nancy Drew, and is heavily inspired by the Data-Sitters Club. For my “Exploring the World of Digital Humanities” course this semester, my final project is to propose a dissertation-length Digital Humanities project. As a huge Nancy Drew fan, I have been interested in doing an NDDH (Nancy Drew Digital Humanities) project for a while now, but I’ve never really had an assignment that was open-ended and long-term enough to make it happen. But, a project proposal is the ideal time to throw out some big project ideas, and test out some methods on a smaller sample data to determine the feasibility of the actual project.
For my final project, I am proposing a project that would analyze the amount of violent content in the Nancy Drew books across the spin-off series, and determine if differences in the level of violence impacted how the books were cataloged, marketed, and distributed in libraries. I was particularly drawn to this topic by having read several installments in the Nancy Drew Files series – the teen-targeted spin-off books written in the ’80s and ’90s. The Files books are wild. Nancy is constantly threatened, there are multiple stalker plots, and several of them even have “Murder” in their titles. The Files books were also the inspiration for many of the HerInteractive PC games, like Secrets Can Kill, Stay Tuned for Danger, and Danger by Design (for the record, I would LOVE to do a text analysis project on the HerInteractive games. If anyone wants to collaborate, let me know!)
Methods
So, how does one measure the level of violence in a text? It’s complicated. One of the big issues in text analysis is context – words that are related to violence in one context may not indicate violence in another. The lexicon that I am choosing to use to identify violence-related words in the Nancy Drew corpus is the Grievance Dictionary, which was developed by sociologists and criminologists at University College London to aid in violent threat assessment. The Grievance Dictionary, henceforth abbreviated as the GD, consists of 22 categories identified by experts in linguistic threat assessment as common features of threats of violence. The GD project team identified seed words in each of the 22 categories, which were then supplemented with words from the GloVe corpus, which provides pre-trained word embeddings. The supplementary words were selected based on their similarity to the seed words, determined by the cosine similarity of the vector representations of the seed word and GloVe words. If none of that makes sense, here’s the TL;DR: the Grievance Dictionary team identified 22 categories of words that often appear in threats of violence, came up with lists of words that fit in each of those 22 categories, and then used a Large Language Model to identify similar words.
Then, the GD team crowdsourced ratings for each of the 24,322 words that they identified for the dictionary; the annotators were given a word and a category, and asked to rank on a scale of 0 to 10 how well they thought that word fit in the category. They were not rating whether they believed it to be a threatening word, just if the word fit into the given category. Each word was rated at least seven times, and then the scores were averaged. The version of the Grievance Dictionary that I will be using in this project contains only the words with an average rating of 7 or higher.
The Grievance Dictionary is a great resource, but it is not perfectly applicable to children’s literature. Not all words in the GD would be read as “violent” in the context of Nancy Drew, and I am still trying to figure out how to modify the GD to be more specific to children’s literature. One change that I have already made is to remove some categories entirely; from the perspective of having read a significant amount of Nancy Drew, I know that language about religion is rarely included, and when it is, it is not in a violent context (the one exception to this may be cult-related language in The Secret of Red Gate Farm). Likewise, relationships are framed as positive in Nancy Drew, as are words related to honor, and children’s literature encourages the reader to seek out help for their problems. For these reasons, I have removed the categories Help Seeking, Relationship, Honor, and God from the Grievance Dictionary for now.
The other avenue of analysis for violent content is a more general analysis of sentiment – is the text generally more positive or more negative? There are also several methods to measure this. In this first sample analysis, I am going to compare two dictionary-based approaches to sentiment analysis: the Valence Aware Dictionary and sEntiment Reader (VADER), and the AFINN Sentiment Lexicon. VADER is “A lexicon and rule-based sentiment analysis tool that is specifically attuned to sentiments expressed in social media, and works well on texts from other domains,” (Katherine Roehrick), and scores words on a scale from -4 to +4. These scores were generated through crowdsourcing via Amazon Mechanical Turk, a platform which has been criticized over and over again for exploitative labor practices (Alana Semuels). In contrast, AFINN was developed by a single person, Finn Årup Nielsen, who started creating a word list in 2009 to better perform sentiment analysis on Tweets; his system rates words from -5 to +5. Because of their methods of production, the dictionaries each have their drawbacks: VADER was produced through exploitative labor practices, but AFINN captures only a single person’s perspective on each word. In order to determine how the relatively smaller scale of AFINN impacts sentiment analysis, I have tested both lexicons, along with the Grievance Dictionary, on a sample of 10 Nancy Drew novels.
Test Data
I acquired .txt files for the first 5 Nancy Drew Mystery Stories novels from the Internet Archive. I also acquired .txt files from The Creative Archive for 5 Nancy Drew Files books; for these titles, I had to copy the text from a PDF. The circumstances under which these PDFs came to be on the Creative Archive website are unclear – we may be in copyright violation territory here. So, that is a future consideration for the viability of the project!
Comparing AFINN and VADER
Overall, AFINN and VADER score the texts fairly similarly. The total range of AFINN scores is from -0.1154 to 0.5455 and the total range of VADER scores is 0.04 to 0.5819. The primary difference between the two is how many words each is able to detect in the text; because VADER is a larger lexicon, it will obviously have sentiment scores for more words in the corpus. I tried converting both the target texts and the AFINN and VADER lexicons to lemmas (lemmas are basically base words – the word “walking”, “walked”, and “walker” would all lemmatize to “walk”), but the number of words that were detected remained consistent.
On average, AFINN is using 8.93% of words per text, and VADER is using 11.93% of words per text, to calculate sentiment scores. I will note that the “word count” here is the total number of tokens comprising the text after stopwords have been removed.
Here is a table to compare the sentiment scores produced by AFINN and VADER for each text:
If you play around with ordering the datatable by the AFINN scores and the VADER scores, you’ll see that the highest-scoring (most positive) book is the same according to both lexicons, as is the lowest scoring (most negative) book: The Secret of the Old Clock is consistently the most positive, and White Water Terror is consistently the most negative. I’ve also included the variable Series to indicate whether each book is from the Nancy Drew Mystery Stores (NDMS) or Nancy Drew Files (Files); from this small sample, it doesn’t seem like the Files books are overwhelmingly more negative than the the NDMS books, but it is notable that the lowest-scoring book is a Files installment that literally has “terror” in its title.
Incorporating the Grievance Dictionary
My implementation of the Grievance Dictionary is a simple count of how many words from each category appear in each book, presented as a proportion of the total word count (after the removal of stopwords) of each book. I’ve also included the proportion of words in each text that do not appear in the Grievance Dictionary, as I think it is important context to note that most words in Nancy Drew books are not present in the GD.
Below is a table showing the texts’ scores in each category of the Grievance Dictionary:
It’s fun to play around with ranking the texts by the various categories, but I also want to highlight some trends that stand out to me in this data. Before I talk numbers, I want to emphasize that the gradations between texts are incredibly small; the vast majority of Nancy Drew words are not in the Grievance Dictionary, so the scores in each category are quite low; also, I am working with a very small sample of the hundreds of Nancy Drew books, so any differences may be due to sampling error right now.
Ok, with those caveats out of the way, let’s dive in to some differences.
- The Files books score noticeably higher than NDMS books for murder, violence, and weaponry, while Mystery Stories books score higher for deadline.
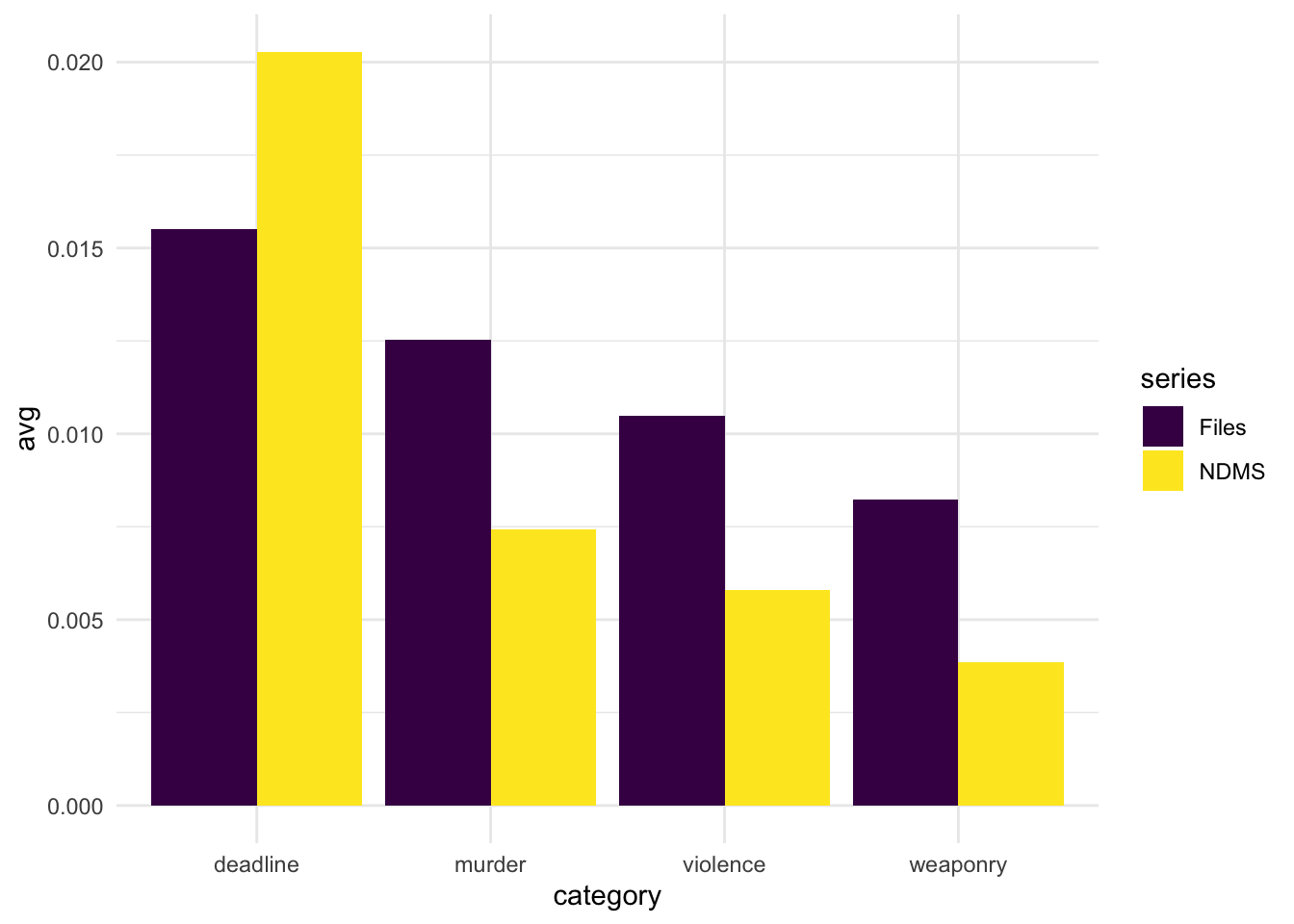
Having read many of the books in my sample, this seems consistent with my recollections of the books. I mean, one of the Files books in this sample is literally called Two Points to Murder, so it’s unsurprising that the Files books have a bit more murder language in them. I am a bit surprised that the NDMS books have more language in the deadline category! The other categories that NDMS scored slightly higher for, although the difference in scores was quite small, were surveillance and impostor – two common themes in Nancy Drew books, further evidenced by surveillance being the most prevalent category for both series. I think it’s important to highlight these categories because violence is not necessarily physical; Nancy may not engage in literal combat in the NDMS books (or at least not in the revised versions – did you know that original 1930s Nancy had a gun?), but there is still a level of threat in all of them. Here’s the breakdown of averages for each category across the NDMS and Files books:
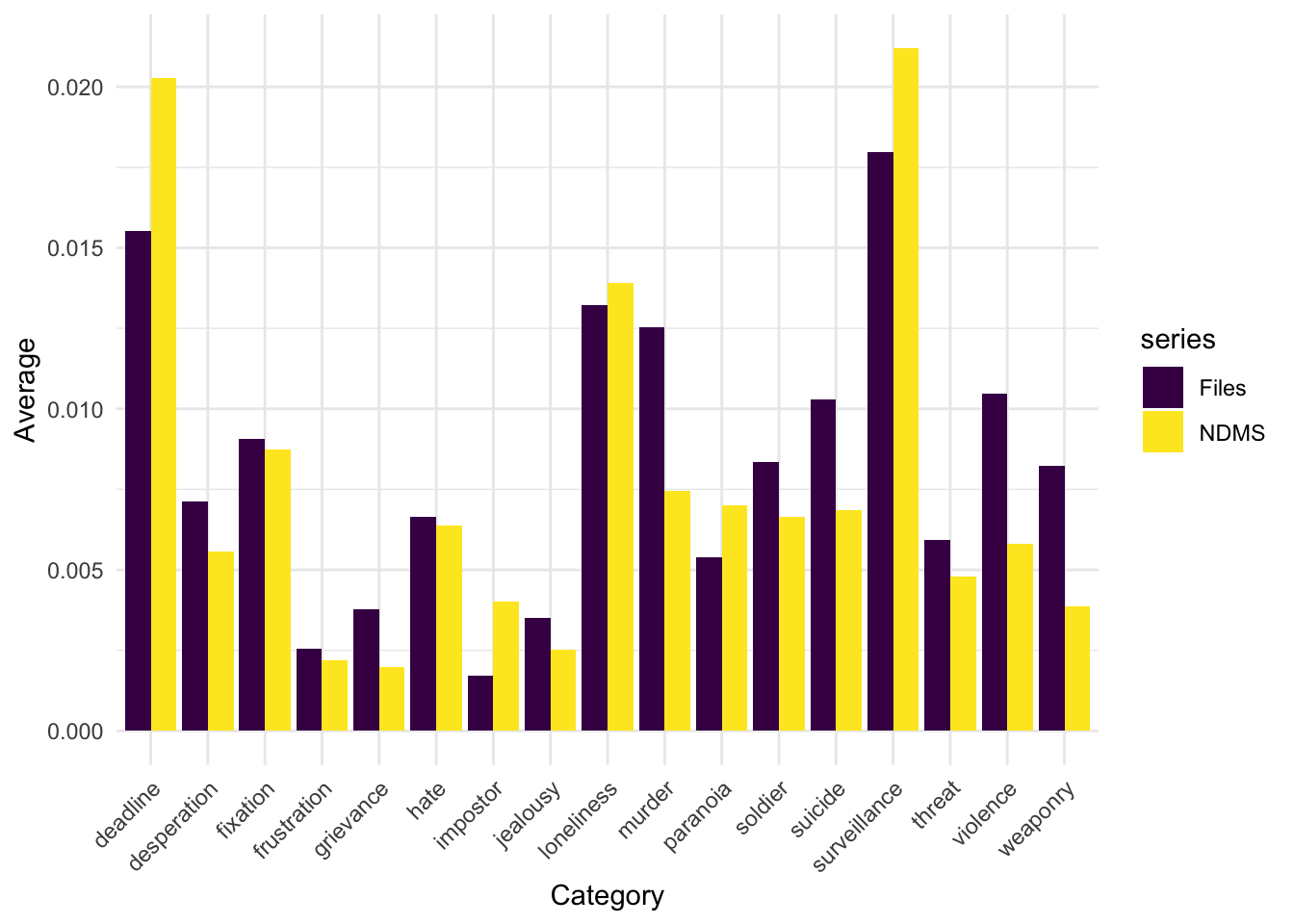
- On average, more words in Files books are present in the Grievance Dictionary.
Again, it’s a really small difference: 0.0131. But a difference nonetheless, and one that indicates that perhaps, overall, the Files books are slightly more violent than the NDMS books. I am super curious about the Files books in general; they are very difficult to find in libraries, were published for a relatively short amount of time in comparison to the general Mystery Stories series, and were the basis for many of the games. They were obviously popular enough in the ’80s and ’90s that Simon & Schuster published so many of them (124 total, according to the Nancy Drew Wiki). So, why are they so hard to find now? Were they never collected by public libraries? Were they deaccessioned, and if so, when were they deemed “too old” to be in teen collections?
Where do I go from here?
I want this project to look beyond just the content of the Nancy Drew books, and towards their perception and presentation in libraries. One way to see whether the differences in violent content were actually noted by adults (specifically librarians and educators) is to analyze how the books were cataloged. As far as I’ve seen, all Nancy Drew books are cataloged in the generic “Juvenile Fiction” age category, despite the Files books being marketed as a “teen” series; however, this is just my anecdotal experience of checking Nancy Drew books out of libraries. Thanks to the Library of Congress Z39.50 gateway, I can theoretically access all of the MARC catalog records for the Nancy Drew books and complete a more thorough analysis, inspired by Vyacheslav Zavalin’s work with children’s literature bibliographic records. In addition to looking for age group classification, I’m also curious about how much the subject and genre tagging varies from series to series; if the Grievance Dictionary results hold true for the wider corpus, then Files books should have more violence-related subject tags, but I have no idea yet if that is the case.
There is so much to talk about with Nancy Drew. With so many iterations of the iconic character, I think we can learn a lot about cultural perceptions of girlhood and what was counted as “girl media” throughout the twentieth century. That’s why I’m taking advantage of this assignment and really nailing down my ideas for a longer-term project that combines this sort of lexicon-based text analysis with analysis of the catalog records, and I look forward to continuing this project in the future!